Unitex/GramLab is an open source, cross-platform, multilingual, lexicon- and grammar-based corpus processing suite. Unitex/GramLab releases are available here. Source code is hosted on GitHub.
This page describes several student projects that could be undertaken to learn about Natural Language Processing (NLP), programming and open source software development practices while simultaneously working on the improvement of Unitex/GramLab. Anyone is welcome to participate as mentor or submitting new projects.
The goal of this module is to compare two sets of annotations.
- Export the two set of annotations to a custom standoff format (C++ | YAML or CSV)
- Efficiently align and compare the annotations (C++)
- Count the number of matched relations which are: Correct, Missing, False positive, Partially correct (C++)
- Calculate metrics over matches: micro and macro values of precision, recall and F-measure (C++)
- Integrate the module into the GramLab IDE (Java)
Note: Some years ago, a former student developed a Perl script named SBDiffTool, a Sentence Boundary Visual Diff Tool for Unitex. A short time later, another student developed several Perl scripts (CiteExtract, CiteDiff, CiteEval) to compare two annotations sets, one set produced by Unitex and other manually labeled by an human. These scripts, which were developed for a very specific class of annotation, could serve as a starting point for build a more flexible and integrated tool.
Mentor: Cristian Martinez
This project was developed under the GSoC'16 program by Mukarram Tailor from the Indian Institute of Technology Mandi, India. Final report is available here.
We need to integrate the two Unitex/GramLab IDEs: the Classic IDE (Unitex.jar) and the Project-oriented IDE (GramLab.jar):
- Classify features according to accessibility from both IDEs or one
- Identify and remove useless dependencies of GramLab.jar on Unitex.jar
- Identify and remove useless differences between the two IDE
- Separate code according to invocation by GramLab.jar or by Unitex.jar only
- Build a welcome wizard to allow users to setup a new project and to select which perspective (the visible actions and views within a window) they want to use: Classic or Project-oriented
Classic IDE (Unitex.jar)
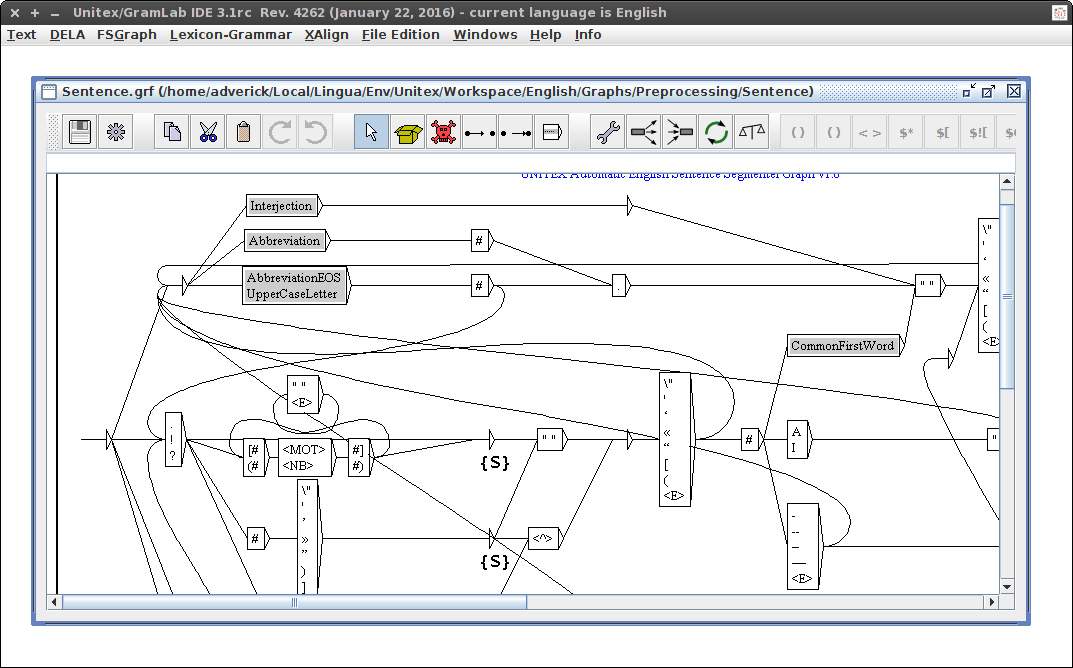
Project-oriented IDE (GramLab.jar)
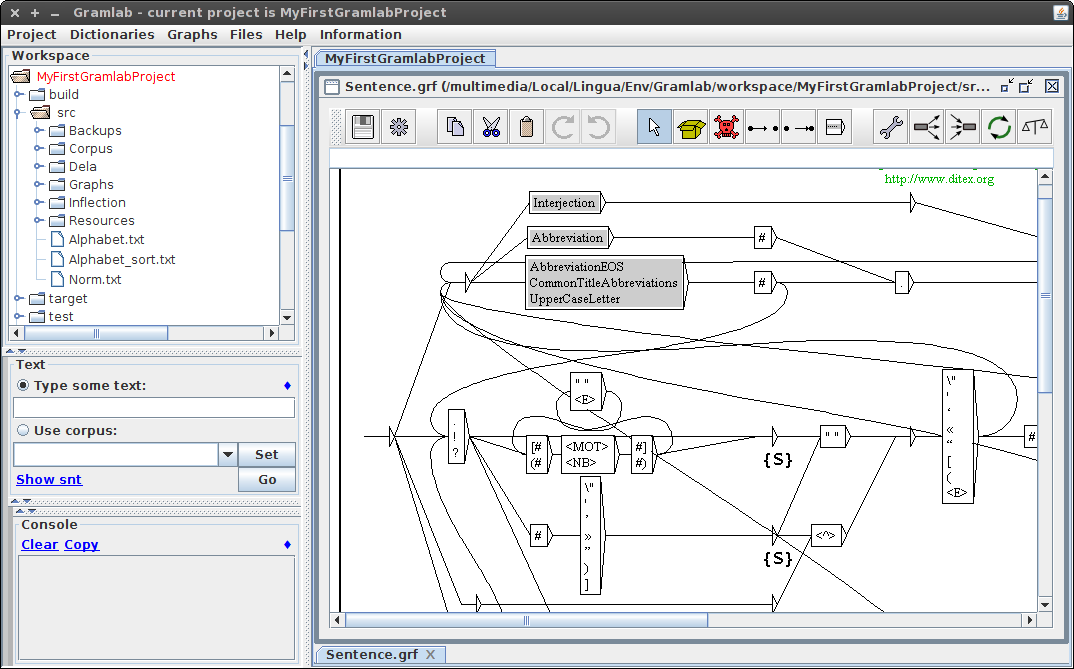
Mentor: Cristian Martinez
MultiFlex is a multi-lingual Unicode-compatible module for automatic inflection of multi-word units (MWUs). It is meant in particular for the creation of morphological dictionaries of MWUs. It implements a unification-based formalism for the description of inflectional behavior of MWUs which supposes the existence of a module for the inflectional morphology of simple words. In the last years, MultiFlex has evolved independently from Unitex. The goal of this project is to enhance the Unitex implementation of MultiFlex backporting these changes in a granular fashion.
- Mentor: Agata Savary
A package manager is a tool that makes installing, upgrading, uninstalling, configuring and managing packages easy. Popular application-level package managers are:
- APM for Atom
- Leiningen for Clojure
- NPM for Node
- CPAN for Perl
- Composer for PHP
- Easy_install for Python
- Gems for Ruby
- Bower for the web
- More here
We wish to provide a Unitex Package Manager (UPM) for Linguistic Resources, i.e. a tool to install, upgrade and uninstall dictionnaires, grammars or a group of language-related resources
Mentor: Cristian Martinez
GATE is an open source infrastructure for developing and deploying software components that process human language. For this project, we are looking to extend Unitex/GramLab to include the next functions :
- A function that exports corpus to GATE with sentence and token delimitation
- A function that exports XML annotated corpus to GATE
- A function that imports GATE corpus to Unitex/GramLab
- A Unitex dialog box that prepares supervised learning with GATE's Learning external module
Mentor: Anubhav Gupta
The Locate Pattern program applies a grammar to a text and constructs an index of the occurrences found. We are looking to support the Locate Pattern on treebanks
- A module that represents a treebank in the form of an acyclic automaton (each internal node of a tree is represented by a transition that bypasses the sequence dominated by the node)
- A variant of the search module that works on treebanks represented in this way
Mentor: Matthieu Constant
Co-mentor: Patrick Watrin
This project was developed under the GSoC'16 program by Aleksandra Chashchina from the National Research University Higher School of Economics, Moscow. Final report is available here.
TreeCloud is a free software visualization tool which display the most frequent words of a text as a tree cloud. A tree cloud is an extension of a tag cloud, in which the words are located around a tree representing how close they appear in the text, and where attributes like size and color are used to reflect the word frequency.

The aim of this project is to integrate a tree cloud visualization for the occurrences that are presented in the concordance window of the Unitex/GramLab IDE (see the User’s Manual p.89). The project will mainly consist in:
- Understanding the Unitex Concord module and the concordance files produced by Unitex.
- Porting from Python (TreeCloud) to Java (Unitex/GramLab IDE) the functions to compute the co-occurrence distance between pairs of words.
- Integrating or re-implementing in Java a tree reconstruction algorithm from the co-occurrence distances between pairs of words; -Integrating or re-implementing in Java a tree visualization algorithm;
- Enhancing the tree visualization to allow users to easily go back to the source text and visualize the context of occurrence of a specific word.
Useful links
- Gambette, P., & Véronis, J. (2010). Visualising a text with a tree cloud. In Classification as a Tool for Research (pp. 561-569). Springer Berlin Heidelberg (https://hal.archives-ouvertes.fr/lirmm-00373643v2/en/).
- TreeCloud website: http://www.treecloud.org
- TreeCloud sources: https://github.com/PhilippeGambette/treecloud
- Plotting phylogenetic trees: http://adamzy.github.io/PhyloPlot/
Mentor: Philippe Gambette
Mentor: Cristian Martinez
Unitex/GramLab includes two Java IDEs, the Classic IDE (Unitex.jar) and the Project-oriented IDE (Gramlab.jar).
During the GSoC'16 a student (see PRJ-02 above) helped us to
deploy a plugin-based architecture to integrate both IDEs into a new one featuring two perspectives: Classical an
Project-oriented. His final report is available here
Plugins are built on PF4J, an open-source, lightweight plugin framework for Java,
with minimal dependencies and easily extensible. Plugins are distributed in ZIP files with all runtime dependencies bundled,
that can be installed without difficulty by copying them into the App/plugins folder.
The aim of this project is to continue the integration of both IDEs. The proposed list of tasks is:
- Migrate core functionalities as plugins (see below)
- Add a feature to convert a projects between perspectives
-
Create a GUI for plugin manager (see image below)

- Configure and deploy an online plugin registry

Some core functionalities to be converted as plugins:
- Concordance viewer as illustrated in the User's Manual, Fig. 4.8.
- Dictionary viewer as illustrated in the User's Manual, Fig. 3.2.
- Graph editor as showed in the User's Manual, Section 5.2.
- Graph exporter as described in the User's Manual, Section 5.4.
- Plugin manager, a user interface to manage plugins.
- Transcoder as illustrated in the User's Manual, Fig. 2.3.
- Xalign as described in the User's Manual, Chapter 10.
- Treecloud, for TreeCloud-style visualization of Unitex concordances.
Tasks for the Community Bonding Period :
- Reproduce and resolve an issue on the PR #52
- Rebase the PR #52 with the latest changes on master
- Ask developers to review the PR #52 and then merge it to master
- Rebase the PR #53 with the latest changes on master
- Ask developers to review the PR #53 and then merge it to master
-
Add a 'Remember Me' feature on the select perspective dialog (see image GramLab Perspective Selection below)


More info:
Mentor: Cristian Martinez
Unitex supports a lexical mask called TDIC that matches any tagged token in the text. Unitex/GramLab 3.1beta version introduced tagging generalization graph that matches user specified tagged token in text and then searches untagged instances of the token. The tagging generalization graph is too restrictive and works only as part of CasSys.
The proposal is to create a new lexical mask, UDIC, in order to combine the functioning of TDIC and tagging generalization graph. This lexical mask has to be written with constraints i.e. <UDIC> is not allowed. It does not accept negations either (!). This mask will lookup untagged instances of a token defined by constraints.
Assume the following tagged token: {TTT,LLL.CCC}, to match all untagged instances of TTT the syntax is <UDIC+CCC>
Mentor: Anubhav Gupta
Unitex has a function to convert the text automaton into a 'POS list' format (FST-Text dialog box, Table pane, 'Export all text as POS list' button).
The project consists in implementing the reverse conversion in case all lexical ambiguity has been removed from the 'POS list' format.
This function was suggested by users that remove lexical ambiguity from corpora manually, but do part of this revision on the 'POS list' format. They want to be able to convert the resulting corpus back to the FST-Text format, so that they can apply search queries on it later.
Mentor: Eric Laporte
Currently, boxes in the text automaton can be manually modified or removed in order to revise the tagging of the text, but it would be useful to be able to add new boxes with new analyses. The difficult part is to deal with the case where parts of a word are tagged separately.
This function was suggested by users that remove lexical ambiguity from corpora manually.
Mentor: Eric Laporte
Currently, the 'Export all graph paths' function (in the FSGraph > Tools menu) lists the paths of a graph and writes them in a file.
If the graph is a morphological dictionary-graph (Manual, Section 3.8.4), it would be useful to extend this function so that it makes an additional processing of the lexical masks in the graph. At each occurrence of a lexical mask, the new function will search the morphological-mode dictionaries for entries which satisfy the mask, and replace the mask with them. The resulting list will be a list of forms with lexical information. Such a list of forms can be converted into a DELAF-format dictionary.
This function would be useful for some languages in which morphosyntax has been encoded with morphological dictionary-graphs (MDG). In Malagasy and Arabic, for example, the word forms described in the MDGs are in finite number and do not run into a combinatorial explosion. It would be interesting to generate all of them into a full-form dictionary, so that Unitex/GramLab can process the language like more weakly inflected languages such as English.
Mentor: Eric Laporte
LexiMir, formerly ILReMaT, is an open-source dictionary manager in C# created at the Language Technology Group of the University of Belgrade (Krstev et al., 2004; Krstev et al., 2013). The project consists in rewriting LexiMir in Java and integrating it into Unitex/GramLab.
LexiMir was designed for dictionary-management tasks not implemented in Unitex/GramLab.
Mentor: Eric Laporte
If you have any questions, please do not hesitate to send a message to the developers mailing list or post back at the users forum.